
语言模型是否会规划未来 token?这篇论文给你答案。
「别让 Yann LeCun 看见了。」
Yann LeCun 表示太迟了,他已经看到了。今天要介绍的这篇 「LeCun 非要看」的论文探讨的问题是:Transformer 是深谋远虑的语言模型吗?当它在某个位置执行推理时,它会预先考虑后面的位置吗?
这项研究得出的结论是:Transformer 有能力这样做,但在实践中不会这样做。
我们都知道,人类会思而后言。数十年的语言学研究表明:人类在使用语言时,内心会预测即将出现的语言输入、词或句子。
不同于人类,现在的语言模型在「说话」时会为每个 token 分配固定的计算量。那么我们不禁要问:语言模型会和人类一样预先性地思考吗?
近期的一些研究已经表明:可以通过探查语言模型的隐藏状态来预测下一 token 之后的更多 token。有趣的是,通过在模型隐藏状态上使用线性探针,可以在一定程度上预测模型在未来 token 上的输出,而干扰隐藏状态则可以对未来输出进行可预测的修改。
这些发现表明在给定时间步骤的模型激活至少在一定程度上可以预测未来输出。
但是,我们还不清楚其原因:这只是数据的偶然属性,还是因为模型会刻意为未来时间步骤准备信息(但这会影响模型在当前位置的性能)?
为了解答这一问题,近日科罗拉多大学博尔德分校和康奈尔大学的三位研究者发布了一篇题为《语言模型是否会规划未来 token?》的论文。

论文标题:Do Language Models Plan for Future Tokens?
论文地址:https://arxiv.org/pdf/2404.00859.pdf
研究概览
他们观察到,在训练期间的梯度既会为当前 token 位置的损失优化权重,也会为该序列后面的 token 进行优化。他们又进一步问:当前的 transformer 权重会以怎样的比例为当前 token 和未来 token 分配资源?
他们考虑了两种可能性:预缓存假设(pre-caching hypothesis)和面包屑假设(breadcrumbs hypothesis)。

预缓存假设是指 transformer 会在时间步骤 t 计算与当前时间步骤的推理任务无关但可能对未来时间步骤 t + τ 有用的特征,而面包屑假设是指与时间步骤 t 最相关的特征已经等同于将在时间步骤 t + τ 最有用的特征。
为了评估哪种假设是正确的,该团队提出了一种短视型训练方案(myopic training scheme),该方案不会将当前位置的损失的梯度传播给之前位置的隐藏状态。
对上述假设和方案的数学定义和理论描述请参阅原论文。
实验结果
为了了解语言模型是否可能直接实现预缓存,他们设计了一种合成场景,其中只能通过显式的预缓存完成任务。他们配置了一种任务,其中模型必须为下一 token 预先计算信息,否则就无法在一次单向通过中准确计算出正确答案。

在这个合成场景中,该团队发现了明显的证据可以说明 transformer 可以学习预缓存。当基于 transformer 的序列模型必须预计算信息来最小化损失时,它们就会这样做。
之后,他们又探究了自然语言模型(预训练的 GPT-2 变体)是会展现出面包屑假设还是会展现出预缓存假设。他们的短视型训练方案实验表明在这种设置中,预缓存出现的情况少得多,因此结果更偏向于面包屑假设。
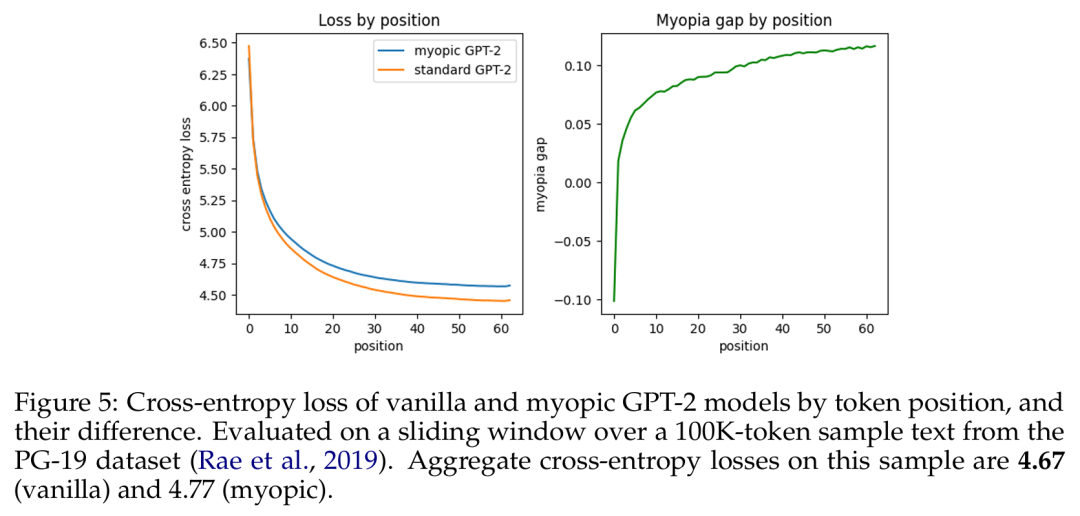
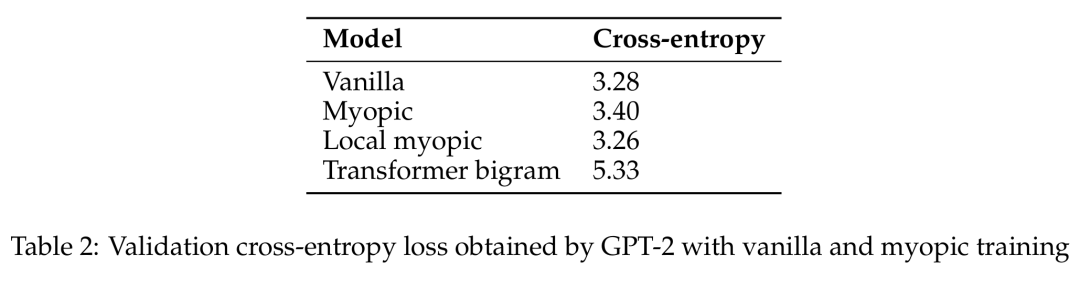
于是该团队声称:在真实语言数据上,语言模型并不会在显著程度上准备用于未来的信息。相反,它们是计算对预测下一个 token 有用的特征 —— 事实证明这对未来的步骤也很有用。

该团队表示:「在语言数据中,我们观察到贪婪地针对下一 token 损失进行优化与确保未来预测性能之间并不存在显著的权衡。」
因此我们大概可以看出来,Transformer 能否深谋远虑的问题似乎本质上是一个数据问题。

可以想象,也许未来我们能通过合适的数据整理方法让语言模型具备人类一样预先思考的能力。
 论文训练
论文训练 

 新浪科技公众号
新浪科技公众号 “掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)
 相关新闻
相关新闻 
